栈与队列
栈只有一个出口,先进后出,意味着是具有 对称性 的,比如函数调用栈,像洋葱一样对称
有效括号
题目描述:给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效。
有效字符串需满足: 左括号必须用相同类型的右括号闭合。左括号必须以正确的顺序闭合。注意空字符串可被认为是有效字符串。
示例 1: 输入: "()" 输出: true
示例 2: 输入: "()[]{}" 输出: true
示例 4: 输入: "([)]" 输出: false
为什么可以用栈做?大家想想,括号成立意味着什么?意味着对称性。
// 用一个 map 来维护左括号和右括号的对应关系
const leftToRight = {
"(": ")",
"[": "]",
"{": "}"
};
/**
* @param {string} s
* @return {boolean}
*/
const isValid = function(s) {
// 结合题意,空字符串无条件判断为 true
if (!s) {
return true;
}
// 初始化 stack 数组
const stack = [];
// 缓存字符串长度
const len = s.length;
// 遍历字符串
for (let i = 0; i < len; i++) {
// 缓存单个字符
const ch = s[i];
// 判断是否是左括号,这里我为了实现加速,没有用数组的 includes 方法,直接手写判断逻辑
if (ch === "(" || ch === "{" || ch === "[") {
// 将右括号入栈
stack.push(leftToRight[ch]);
}
// 若不是左括号,则必须是和栈顶的左括号相配对的右括号
else {
// 若栈为空,或栈顶的左括号没有和当前字符匹配上,那么判为无效
if (!stack.length || stack.pop() !== ch) {
return false;
}
}
}
// 若所有的括号都能配对成功,那么最后栈应该是空的
return !stack.length;
};每日温度
请根据每日 气温 列表,重新生成一个列表。对应位置的输出为:要想观测到更高的气温,至少需要等待的天数。如果气温在这之后都不会升高,请在该位置用 0 来代替。
输入:temperatures = [73, 74, 75, 71, 69, 72, 76, 73],输出:[1, 1, 4, 2, 1, 1, 0, 0]
定义一个递减的栈, 如果遍历到的元素打破了 递减 操作,说明是温度比较高的元素,在递减栈中,所有小于这个元素的都要 出栈,这个 栈 只需要存储下标即可
var dailyTemperatures = function(temperatures) {
const n = temperatures.length;
const res = Array(n).fill(0);
const stack = []; // 递增栈:用于存储元素右面第一个比他大的元素下标
stack.push(0);
for (let i = 1; i < n; i++) {
while (stack.length && temperatures[i] > temperatures[stack[stack.length - 1]]) {
const top = stack.pop();
res[top] = i - top;
}
stack.push(i);
}
return res;
};下一个更大元素 I
给定两个 没有重复元素 的数组 nums1 和 nums2 ,其中 nums1 是 nums2 的子集。找到 nums1 中每个元素在 nums2 中的下一个比其大的值。,如果不存在,则将其置为 -1。
示例 1:
输入: nums1 = [4,1,2], nums2 = [1,3,4,2].
输出: [-1,3,-1]
解释:
对于 num1 中的数字 4 ,你无法在第二个数组中找到下一个更大的数字,因此输出 -1 。 对于 num1 中的数字 1 ,第二个数组中数字 1 右边的下一个较大数字是 3 。 对于 num1 中的数字 2 ,第二个数组中没有下一个更大的数字,因此输出 -1 。
示例 2:
输入: nums1 = [2,4], nums2 = [1,2,3,4].
输出: [3,-1]
解释:
对于 num1 中的数字 2 ,第二个数组中的下一个较大数字是 3 。 对于 num1 中的数字 4 ,第二个数组中没有下一个更大的数字,因此输出-1 。
- 暴力解法
function L(nums1, nums2) {
let stack = Array(nums1.length).fill(-1);
for (let i = 0; i < nums1.length; i++) {
let j = nums1.findIndex(item => item > nums2[i]);
if (j === -1) {
continue
}
for (; j < nums2.length; j++) {
if (nums2[j] > nums1[i]) {
stack[i] = nums2[j];
break;
}
}
}
return stack;
}
let r = L([2,4], [1,2,3,4]);- 单调栈 :::info 注意题目中说是两个没有重复元素 的数组 nums1 和 nums2。
没有重复元素,我们就可以用 map 来做映射了。根据数值快速找到下标,还可以判断 nums2[i]是否在 nums1 中出现过。
单调递增栈 :::
var nextGreaterElement = function (nums1, nums2) {
let stack = [];
let map = new Map();
for (let i = 0; i < nums2.length; i++) {
while (stack.length && nums2[i] > nums2[stack[stack.length - 1]]) {
let index = stack.pop();
map.set(nums2[index], nums2[i]);
}
stack.push(i);
}
// 构建单调递增栈
// Map { 1 => 2, 2 => 3, 3 => 4 }
// map
let res = [];
for (let j = 0; j < nums1.length; j++) {
res[j] = map.get(nums1[j]) || -1;
}
return res;
};
let r1 = nextGreaterElement([2,4], [1,2,3,4])接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
 输入:height = [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
输入:height = [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。 暴力解法
//暴力解法
var trap = function(height) {
const len = height.length;
let sum = 0;
for(let i = 0; i < len; i++){
// 第一个柱子和最后一个柱子不接雨水
if(i == 0 || i == len - 1) continue;
let rHeight = height[i]; // 记录右边柱子的最高高度
let lHeight = height[i]; // 记录左边柱子的最高高度
for(let r = i + 1; r < len; r++){
if(height[r] > rHeight) rHeight = height[r];
}
for(let l = i - 1; l >= 0; l--){
if(height[l] > lHeight) lHeight = height[l];
}
let h = Math.min(lHeight, rHeight) - height[i];
if(h > 0) sum += h;
}
return sum;
};单调栈 js 数组作为栈
var trap = function(height) {
const len = height.length;
if(len <= 2) return 0; // 可以不加
const st = [];// 存着下标,计算的时候用下标对应的柱子高度
st.push(0);
let sum = 0;
for(let i = 1; i < len; i++){
if(height[i] < height[st[st.length - 1]]){ // 情况一
st.push(i);
}
if (height[i] == height[st[st.length - 1]]) { // 情况二
st.pop(); // 其实这一句可以不加,效果是一样的,但处理相同的情况的思路却变了。
st.push(i);
} else { // 情况三
while (st.length !== 0 && height[i] > height[st[st.length - 1]]) { // 注意这里是while
let mid = st[st.length - 1];
st.pop();
if (st.length !== 0) {
let h = Math.min(height[st[st.length - 1]], height[i]) - height[mid];
let w = i - st[st.length - 1] - 1; // 注意减一,只求中间宽度
sum += h * w;
}
}
st.push(i);
}
}
return sum;
};队列
双端队列
双端队列就是允许在队列的两端进行插入和删除的队列
体现在编码上,最常见的载体是既允许使用 pop、push 同时又允许使用 shift、unshift 的数组:
const queue = [1,2,3,4] // 定义一个双端队列
queue.push(1) // 双端队列尾部入队
queue.pop() // 双端队列尾部出队
queue.shift() // 双端队列头部出队
queue.unshift(1) // 双端队列头部入队滑动窗口问题
题目描述:给定一个数组 nums 和滑动窗口的大小 k,请找出所有滑动窗口里的最大值。
示例: 输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3 输出: [3,3,5,5,6,7]
双指针
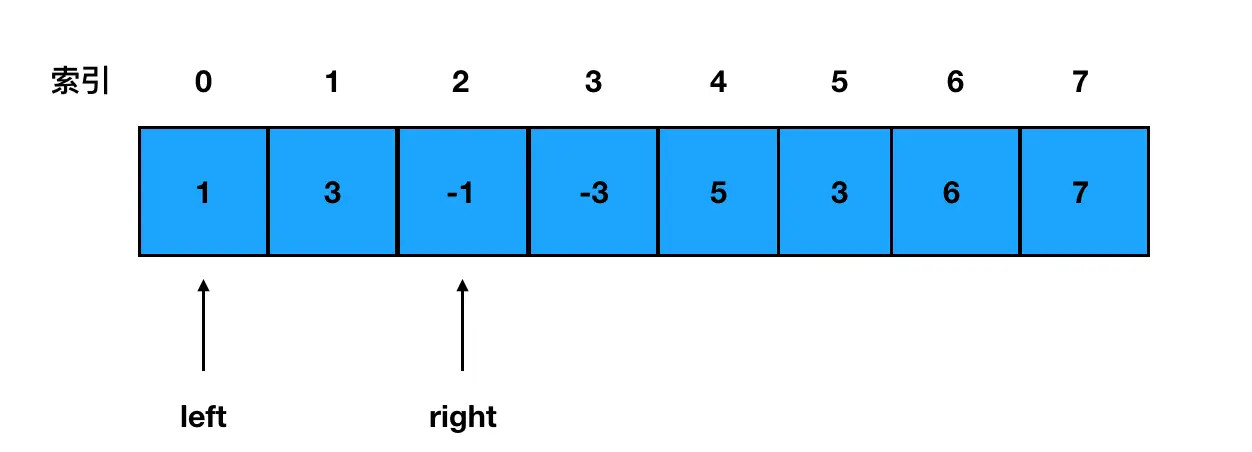
接下来我们可以把这个窗口里的数字取出来,直接遍历一遍、求出最大值,然后把最大值存进结果数组。
/**
* @param {number[]} nums
* @param {number} k
* @return {number[]}
*/
const maxSlidingWindow = function (nums, k) {
// 缓存数组的长度
const len = nums.length;
// 定义结果数组
const res = [];
// 初始化左指针
let left = 0;
// 初始化右指针
let right = k - 1;
// 当数组没有被遍历完时,执行循环体内的逻辑
while (right < len) {
// 计算当前窗口内的最大值
const max = calMax(nums, left, right);
// 将最大值推入结果数组
res.push(max);
// 左指针前进一步
left++;
// 右指针前进一步
right++;
}
// 返回结果数组
return res;
};
// 这个函数用来计算最大值
function calMax(arr, left, right) {
// 处理数组为空的边界情况
if (!arr || !arr.length) {
return;
}
// 初始化 maxNum 的值为窗口内第一个元素
let maxNum = arr[left];
// 遍历窗口内所有元素,更新 maxNum 的值
for (let i = left; i <= right; i++) {
if (arr[i] > maxNum) {
maxNum = arr[i];
}
}
// 返回最大值
return maxNum;
}🔗双端队列法
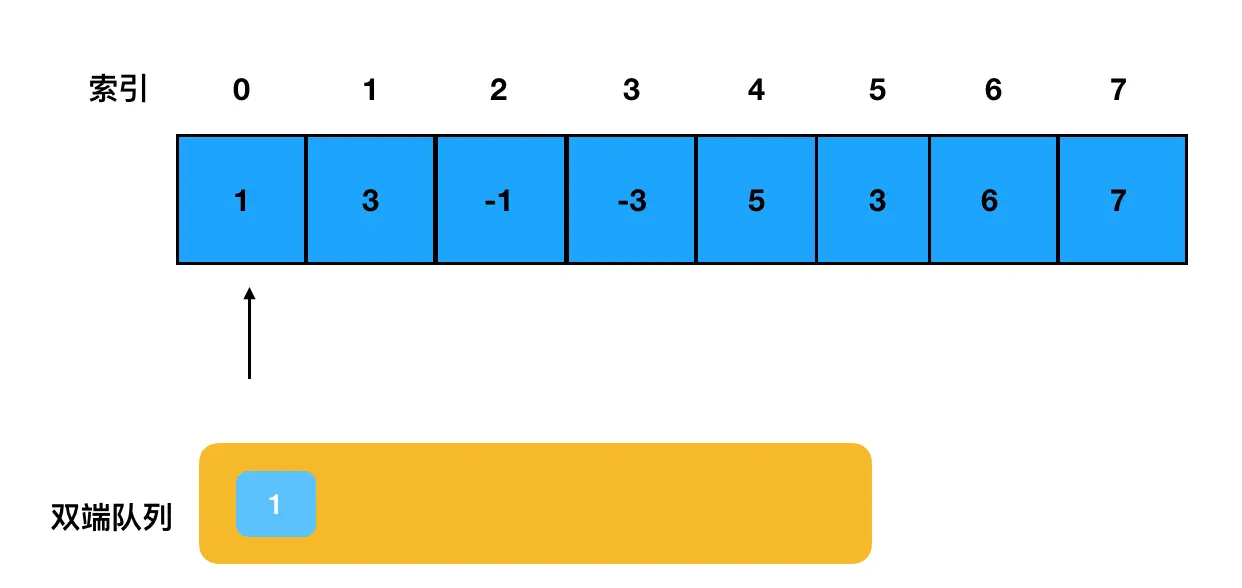
每尝试推入一个元素前,都把这个元素与队列尾部的元素作对比。根据对比结果的不同,采取不同的措施:
- 如果试图推入的元素(当前元素)大于队尾元素,则意味着队列的递减趋势被打破了。此时我们需要将队列尾部的元素依次出队(注意由于是双端队列,所以队尾出队是没有问题的)、直到队尾元素大于等于当前元素为止,此时再将当前元素入队。
- 如果试图推入的元素小于队列尾部的元素,那么就不需要额外的操作,直接把当前元素入队即可。
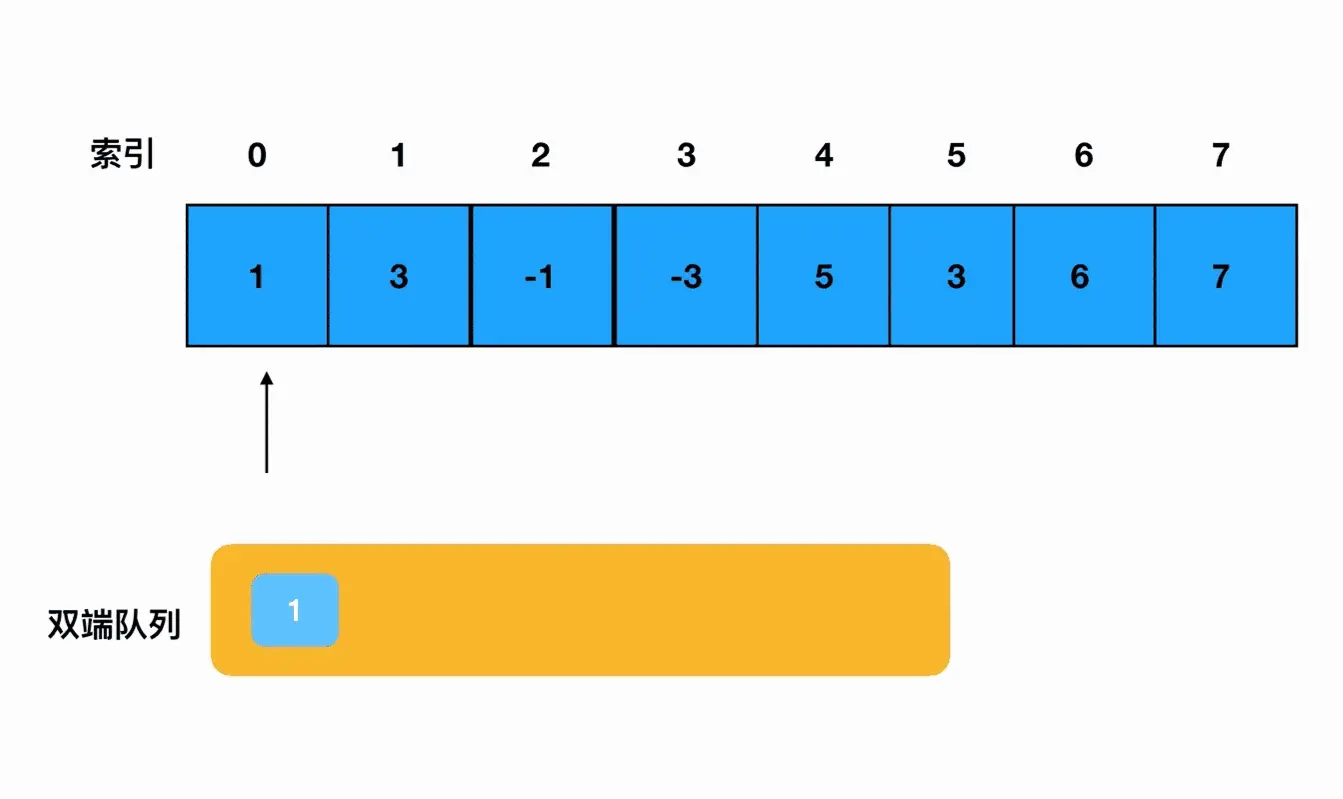
维持递减队列的目的,就在于确保队头元素始终是当前窗口的最大值。
当遍历到的元素个数达到了 k 个时,意味着滑动窗口的第一个最大值已经产生了,我们把它 push 进结果数组里: 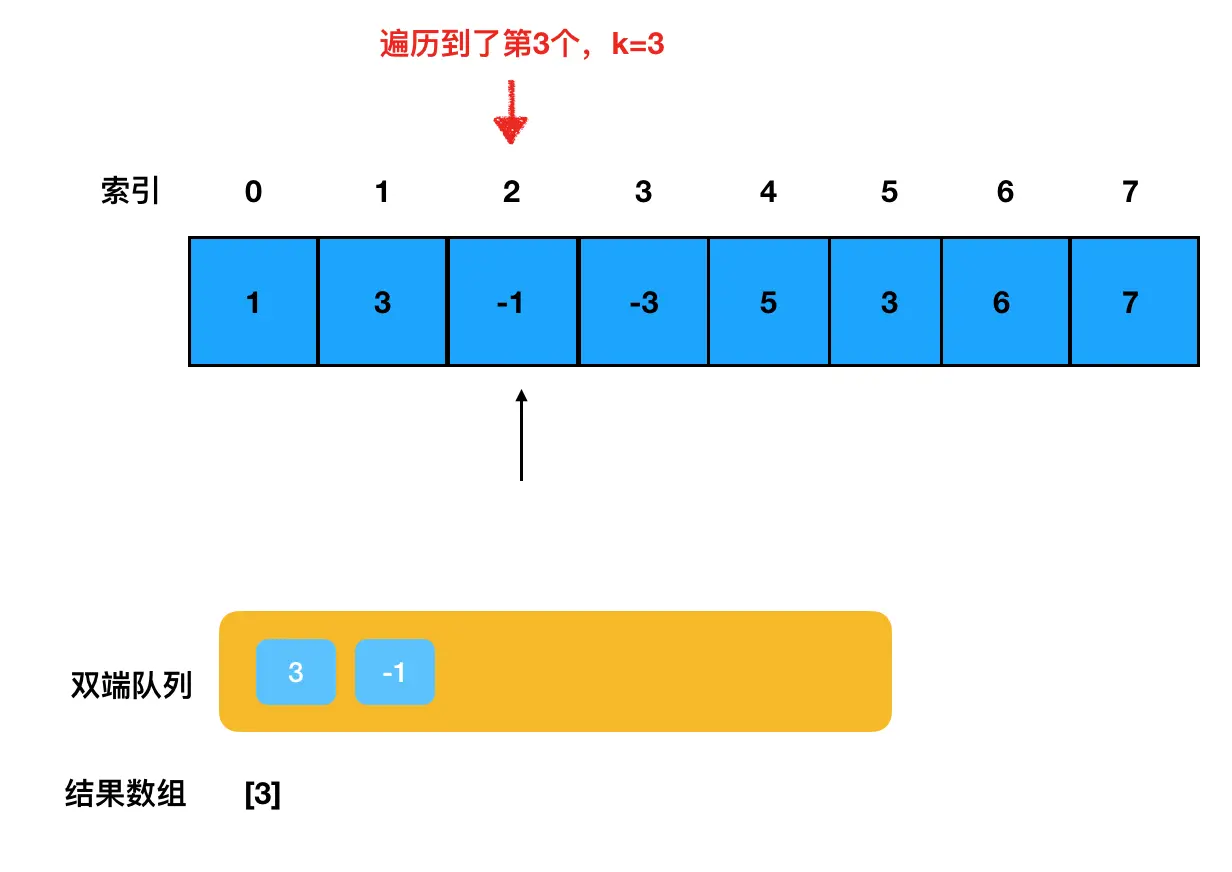
为了确保队列的有效性,需要及时地去队列检查下 1 这个元素在不在队列里(在的话要及时地踢出去,因为队列本身只维护当前滑动窗口内的元素)。 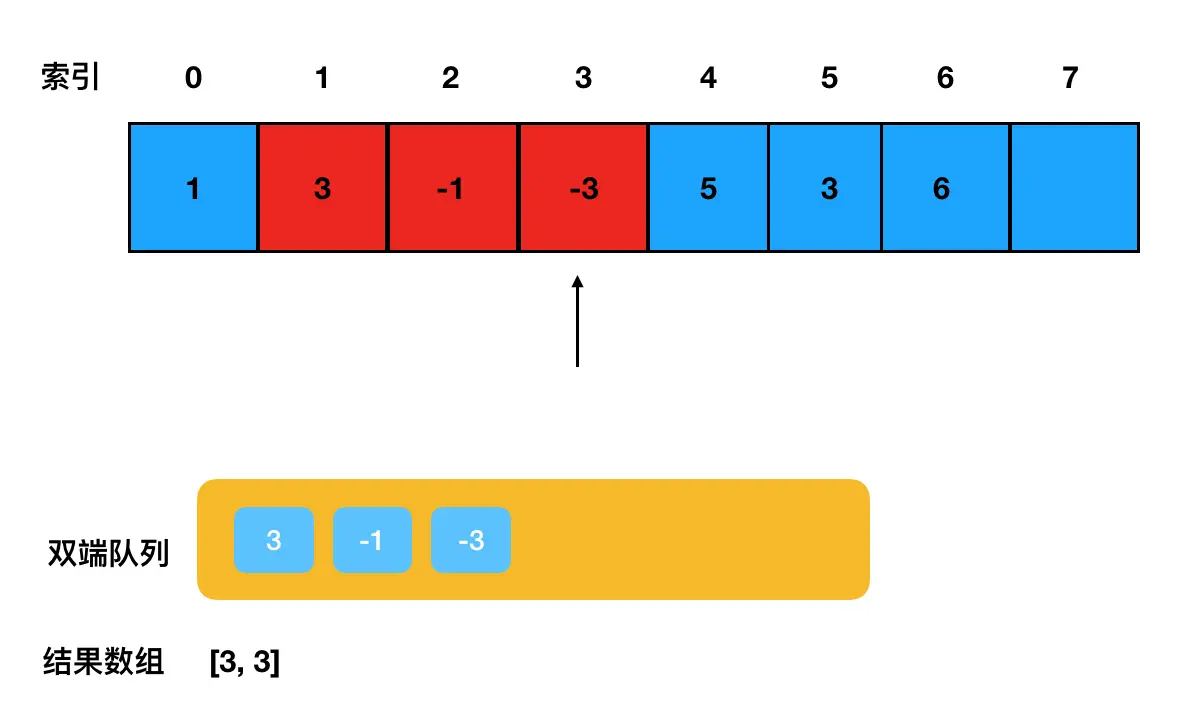
在查找 1 的时候,需不需要遍历整个队列?答案是不需要,因为 1 是最靠前的一个元素,如果它在,那么它一定是队头元素。这里我们只需要检查队头元素是不是 1 就行了。 此时我们检查队头,发现是 3:
- 检查队尾元素,看是不是都满足大于等于当前元素的条件。如果是的话,直接将当前元素入队。否则,将队尾元素逐个出队、直到队尾元素大于等于当前元素为止。
- 将当前元素入队
- 检查队头元素,看队头元素是否已经被排除在滑动窗口的范围之外了。如果是,则将队头元素出队。
- 判断滑动窗口的状态:看当前遍历过的元素个数是否小于 k。如果元素个数小于k,这意味着第一个滑动窗口内的元素都还没遍历完、只能继续更新队列;如果元素个数大于等于k,这意味着滑动窗口的最大值已经出现了,此时每遍历到一个新元素(也就是滑动窗口每往前走一步)都要及时地往结果数组里添加当前滑动窗口对应的最大值(最大值就是此时此刻双端队列的队头元素)。
- 维持队列的递减性:确保队头元素是当前滑动窗口的最大值。这样我们每次取最大值时,直接取队头元素即可。
- 这一步没啥好说的,就是在维持队列递减性的基础上、更新队列的内容。
- 维持队列的有效性:确保队列里所有的元素都在滑动窗口圈定的范围以内。
- 排除掉滑动窗口还没有初始化完成、第一个最大值还没有出现的特殊情况。
/**
* @param {number[]} nums
* @param {number} k
* @return {number[]}
*/
const maxSlidingWindow = function (nums, k) {
// 缓存数组的长度
const len = nums.length;
// 初始化结果数组
const res = [];
// 初始化双端队列
const deque = [];
// 开始遍历数组
for (let i = 0; i < len; i++) {
// 当队尾元素小于当前元素时,只要最大值
while (deque.length && nums[deque[deque.length - 1]] < nums[i]) {
// 将队尾元素(索引)不断出队,直至队尾元素大于等于当前元素
// 就算弹出完也无所谓,最大值那就是当前值
deque.pop();
}
// 入队当前元素索引(注意是索引)
deque.push(i);
// 当队头元素的索引已经被排除在滑动窗口之外时
while (deque.length && deque[0] <= i - k) {
// 将队头元素索引出队
deque.shift();
}
// 判断滑动窗口的状态,只有在被遍历的元素个数大于 k 的时候,才更新结果数组
if (i >= k - 1) {
res.push(nums[deque[0]]);
}
}
// 返回结果数组
return res;
};DFS深度优先搜索/ BFS广度优先搜索
INFO
想象你在一个迷宫里,不知道路径,只能一个一个试验,当遇到分叉路口时,就进去,如果里面还有分叉路口,再次进去,如果不是就退出来
DFS深度优先搜索
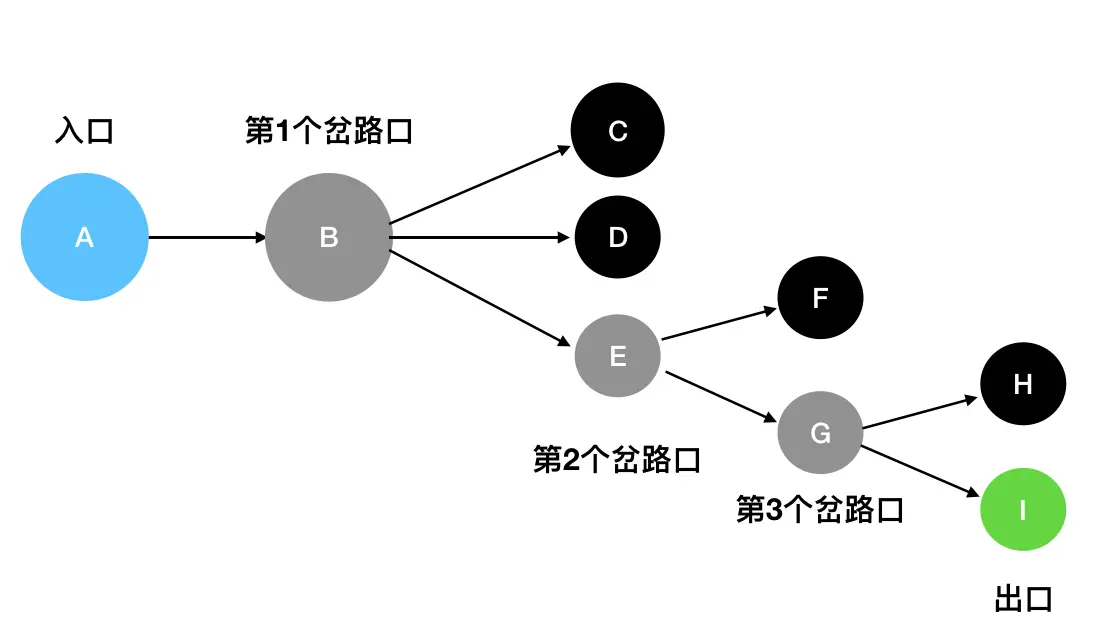
- 从 A 出发(A入栈),经过了B(B入栈),接下来面临 C、D、E三条路。这里按照从上到下的顺序来走(你也可以选择其它顺序),先走C(C入栈)。
- 发现 C是死胡同,后退到最近的岔路口 B(C出栈),尝试往D方向走(D入栈)。
- 发现D 是死胡同,,后退到最近的岔路口 B(D出栈),尝试往E方向走(E入栈)。
- E 是一个岔路口,眼前有两个选择:F 和 G。按照从上到下的顺序来走,先走F(F入栈)。 发现F 是死胡同,后退到最近的岔路口 E(F出栈),尝试往G方向走(G入栈)。
- G 是一个岔路口,眼前有两个选择:H 和 I。按照从上到下的顺序来走,先走H(H入栈)。 发现 H 是死胡同,后退到最近的岔路口 G(H出栈),尝试往I方向走(I入栈)。
- I 就是出口,成功走出迷宫。
此时栈里面的内容就是A、B、E、G、I,因此 A->B->E->G->I 就是走出迷宫的路径。通过深度优先搜索,我们不仅可以定位到迷宫的出口,还可以记录下相关的路径信息。
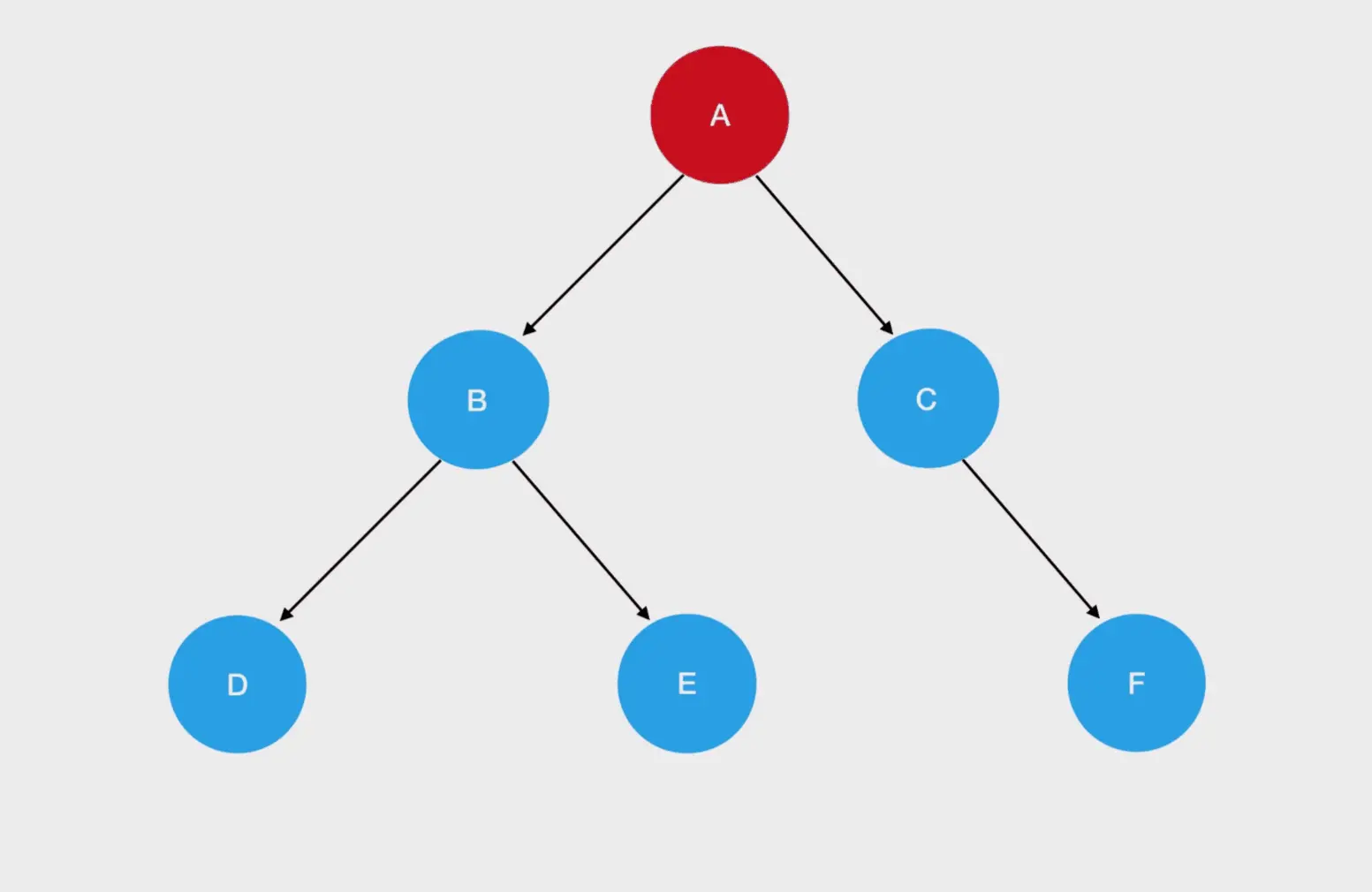
// 所有遍历函数的入参都是树的根结点对象
function preorder(root) {
// 递归边界,root 为空
if(!root) {
return
}
// 输出当前遍历的结点值
console.log('当前遍历的结点值是:', root.val)
// 递归遍历左子树
preorder(root.left)
// 递归遍历右子树
preorder(root.right)
}在这个递归函数中,递归式用来先后遍历左子树、右子树(分别探索不同的道路),递归边界在识别到结点为空时会直接返回(撞到了南墙,相当于在迷宫里碰到了墙壁,然后退到最近的一个节点处)因此,我们可以认为,递归式就是我们选择道路的过程,而递归边界就是死胡同(函数执行完毕相当于已经这个节点搜寻完毕,该去下一个节点了)。
BFS广度优先搜索思想
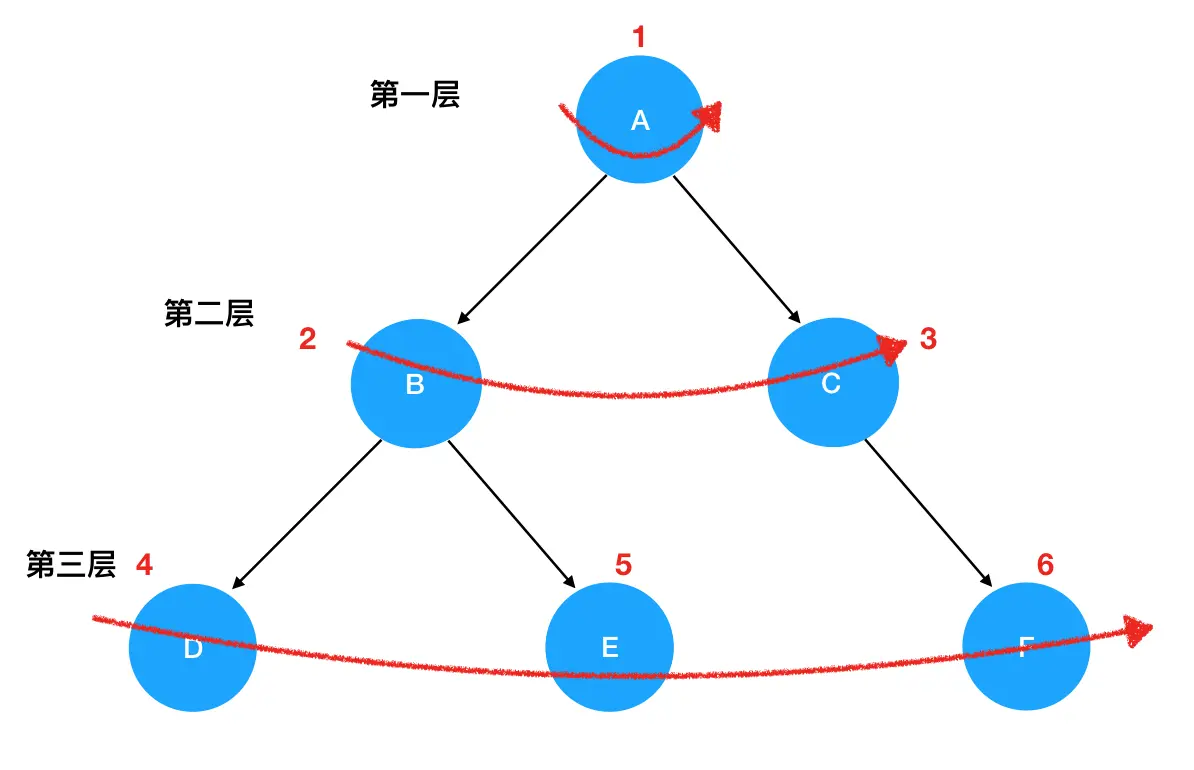
比如说站在 B 这个岔路口,它会只关注 C、D、E 三个坐标,至于 F、G、H、I这些遥远的坐标,现在不在它的关心范围内:类似于扫描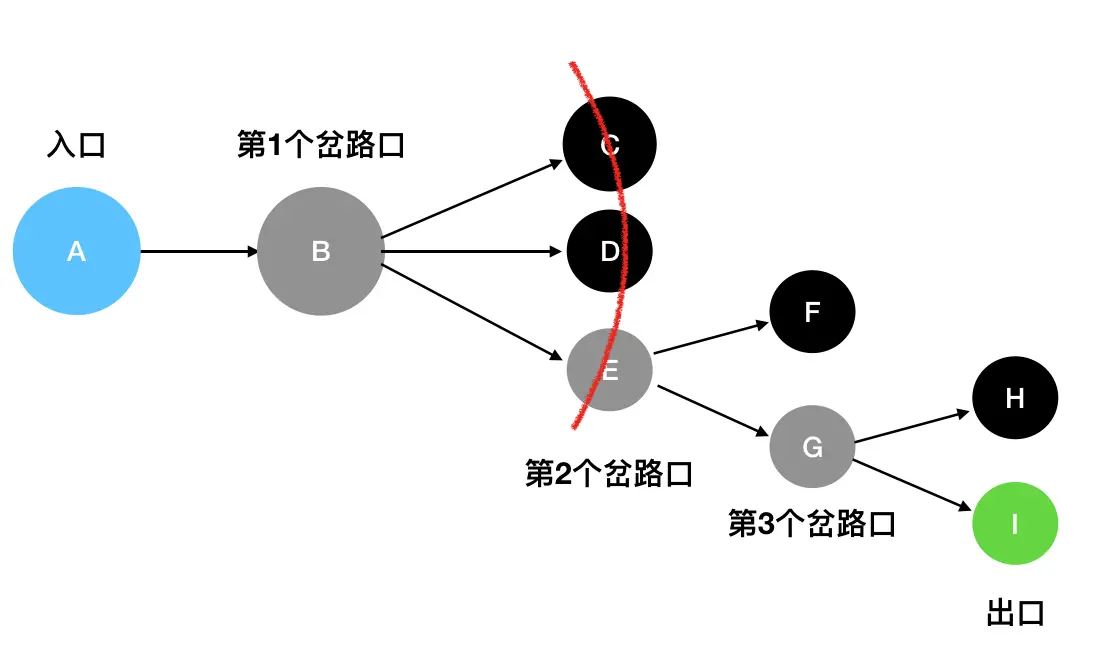
只有在走到了 E处时,它发现此时可以触达的坐标变成了 F、G,此时才会去扫描F、G: 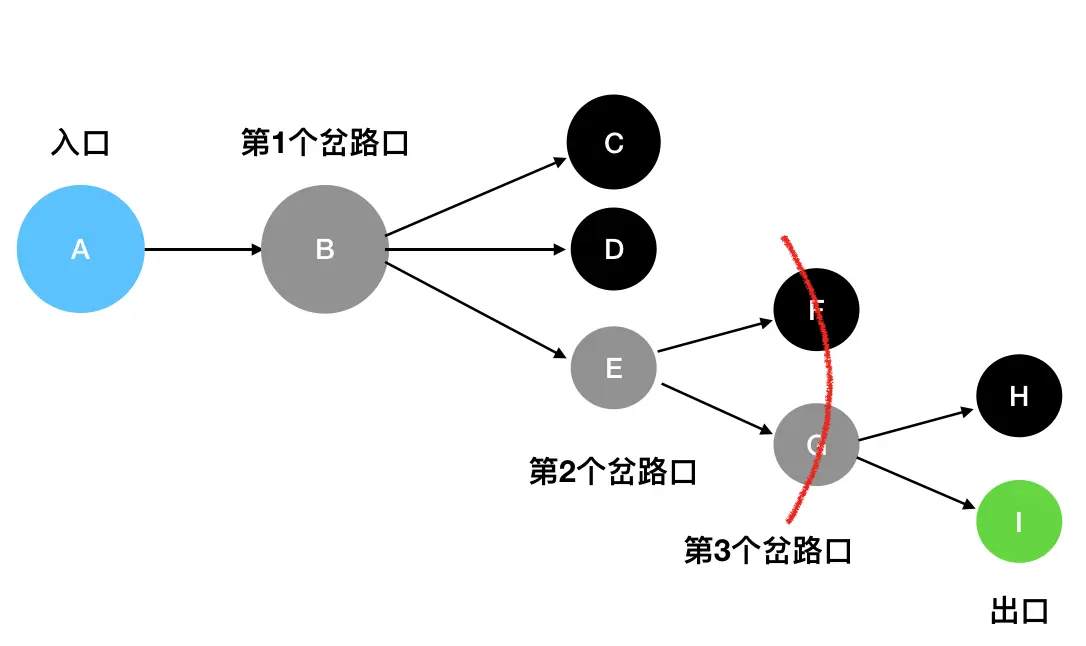
- 站在入口A处(第一层),发现直接能抵达的坐标只有B,于是接下来需要访问的就是 B。
- 入口A访问完毕,走到 B 处(第二层),发现直接能抵达的坐标变成了C、D和E,于是把这三个坐标记为下一层的访问对象。
- B访问完毕,访问第三层。这里我按照从上到下的顺序(你也可以按照其它顺序),先访问 C和D,然后访问E。站在C处和D处都没有见到新的可以直接抵达的坐标,所以不做额外的动作。但是在E处见到了可以直接抵达的F和G,因此把F和G记为下一层(第四层)需要访问的对象。
- 第三层访问完毕,访问第四层。第四层按照从上到下的顺序,先访问的是 F。从F出发没有可以直接触达的坐标,因此不做额外的操作。接着访问G,发现从G出发可以直接抵达H和I,因此把H和I记为下一层(第五层)需要访问的对象。
- 第四层访问完毕,访问第五层。第五层按照从上到下的顺序,先访问的是H,发现从H出发没有可以直接抵达的坐标,因此不作额外的操作。接着访问I,发现I就是出口,问题得解。
在分层遍历的过程中,大家会发现两个规律:
- 每访问完毕一个坐标,这个坐标在后续的遍历中都不会再被用到了,也就是说它可以被丢弃掉。
- 站在某个确定坐标的位置上,我们所观察到的可直接抵达的坐标,是需要被记录下来的,因为后续的遍历还要用到它们
丢弃已访问的坐标、记录新观察到的坐标,这个顺序毫无疑问符合了“先进先出”的原则,因此整个 BFS 算法的实现过程,和队列有着密不可分的关系。
function BFS(入口坐标) {
const queue = [] // 初始化队列queue
// 入口坐标首先入队
queue.push(入口坐标)
// 队列不为空,说明没有遍历完全
while(queue.length) {
const top = queue[0] // 取出队头元素
访问 top // 此处是一些和 top 相关的逻辑,比如记录它对应的信息、检查它的属性等等
// 相当于扫描
for(检查 top 元素出发能够遍历到的所有元素) {
queue.push(top能够直接抵达的元素)
}
queue.shift() // 访问完毕。将队头元素出队
}
}
const root = {
val: "A",
left: {
val: "B",
left: {
val: "D"
},
right: {
val: "E"
}
},
right: {
val: "C",
right: {
val: "F"
}
}
};function BFS(root) {
const queue = [] // 初始化队列queue
// 根结点首先入队
queue.push(root)
// 队列不为空,说明没有遍历完全
while(queue.length) {
const top = queue[0] // 取出队头元素
// 访问 top
console.log(top.val)
// 如果左子树存在,左子树入队
if(top.left) {
queue.push(top.left)
}
// 如果右子树存在,右子树入队
if(top.right) {
queue.push(top.right)
}
queue.shift() // 访问完毕,队头元素出队
}
}
// A B C D E F
BFS(root)