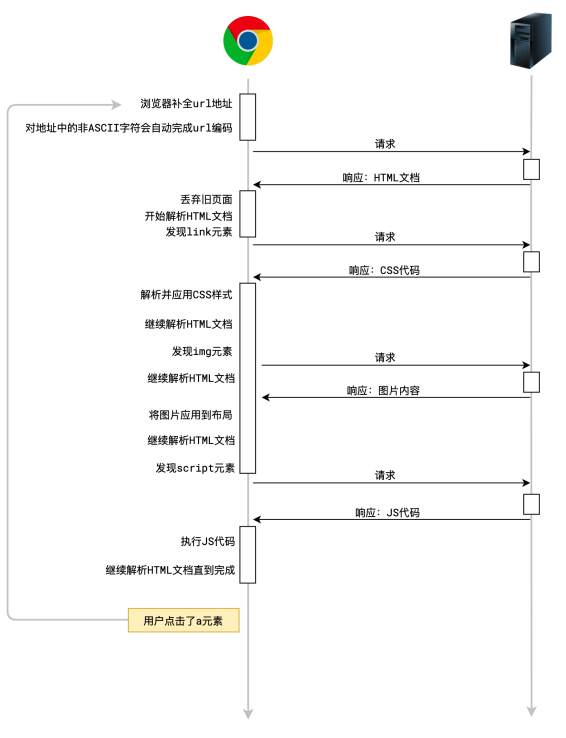
网络
在网络层面,对于前端开发者,必须要知道浏览器拥有的两大核心能力:
- 自动发出请求的能力
- 自动解析响应的能力
Get / Post 的区别
当发送GET请求时,浏览器不会附带请求体
- GET 请求只能传递 ASCII 数据,遇到非 ASCII 数据需要进行编码;POST 请求没有限制
- POST 不会被保存到浏览器的历史记录中
- 刷新页面时,若当前的页面是通过 POST 请求得到的,则浏览器会提示用户是否重新提交。若是 GET 请求得到的页面则没有提示。
自动解析响应的能力
- 浏览器能够自动识别响应码,当出现一些特殊的响应码时浏览器会自动完成处理,比如301( 永久 重定向 )、302( 临时重定向 )
- 根据响应结果做不同的处理浏览器能够自动分析响应头中的Content-Type,根据不同的值进行不同处理,比如:
- text/plain: 普通的纯文本,浏览器通常会将响应体原封不动的显示到页面上
- text/html:html文档,浏览器通常会将响应体作为页面进行渲染
- text/javascript 或 application/javascript:js代码,浏览器通常会使用JS执行引擎将它解析执行
- text/css:css代码,浏览器会将它视为样式
- image/jpeg:浏览器会将它视为jpg图片
- application/octet-stream:二进制数据,会触发浏览器下载功能
- attachment:附件,会触发下载功能该值和其他值不同,应放到Content-Disposition头中。
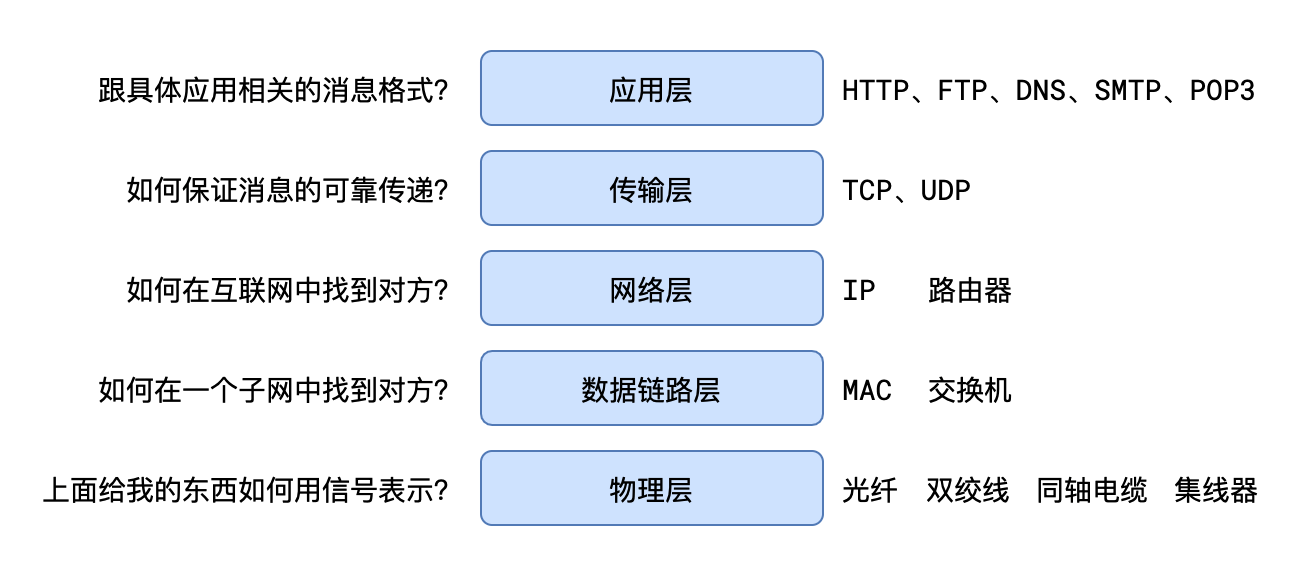
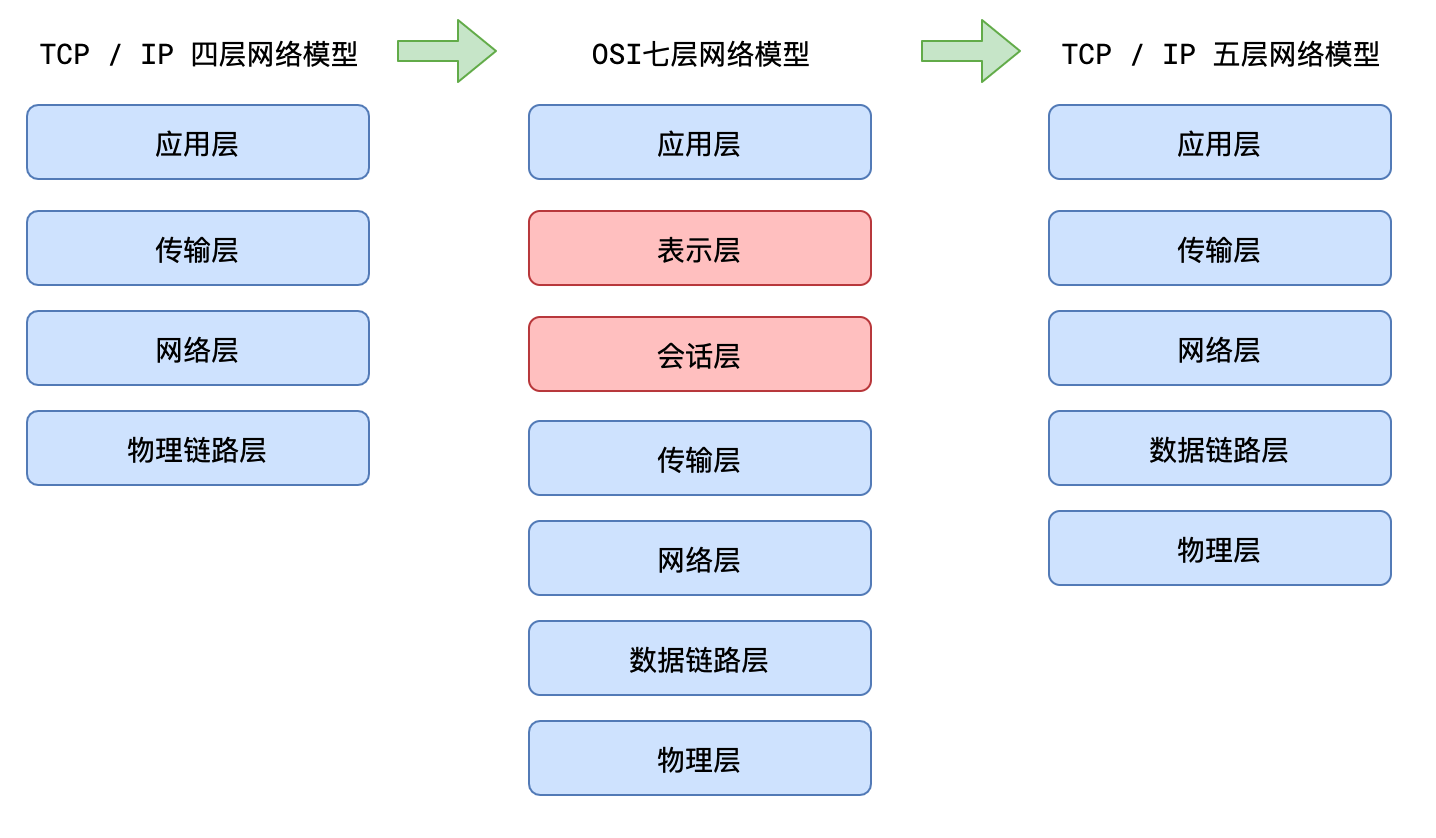
七层协议
应用层
- 两个软件可以通过网络通信,那么这两个软件就是应用层
- 应用层有很多协议
HTTPFTP(文件传输)DNS协议(域名解析)- SMTP协议(邮件传输)
这些协议类似于包装层的方案选择什么来装鱼,黑色袋子、麻袋、还是揣兜里,用于处理不同的场景
传输层
- 传输层主要是保证消息的可靠传递
- 传输层协议
- UDP协议(User Datagram Protocol,用户数据报协议)
- TCP协议(Transmission Control Protocol,传输控制协议)
网络层
- IP(Internet Protocol)协议
- 网络层会接收到来自传输层的“数据”,然后将这些数据拆分很多片段,主要是为了方便IP数据包的发送,理论上每个数据包最多可以存储64KB,但实际上数据包不超过1500个字节,IP路由器会转发每一个数据包,沿着一条路径从一台路由器传递到下一台路由器,直到达到目的地,然后会在网络层重组,因为数据是有一个封装和解封装的过程
数据链路层
数据链路层的代表就是MAC协议(medium access control,介质访问控制)
MAC地址相当于我们的身份证号,无论我们在哪个城市,它都是唯一不变的,而IP地址换个城市就会变
物理层
二进制数据可以用光纤、双绞线、同轴电缆、电力线等等,像这些传输的介质我们一般称为导向的传输介质

TCP
三次握手,四次挥手
三次握手
当发送的数据过大时,会被分成一段一段的数据报,每一段数据报头部都会有TCP头部,这里面包含了很多信息,其中就有上图中的 SYN(Synchronize Sequence Numbers,同步序列编号,是连接建立的握手信号), seq(sequence,数据报序号),ACK(Acknowledge character,确认字符,只有0和1), seq(下次应该发送的编号)
- 每个链接都是从CLOSED状态开始的,当它执行一个主动打开连接操作或者被动打开连接操作,它就离开了CLOSED状态
- 当客户端A向服务器B发送消息的时候,链接从CLOSED状态进入SYN-SENT状态
- TCP头部携带SYN=1表示 A 要跟 B 建立同步链接、seq=x表示这次发送的是序号为x的数据报、ACK=0表示还未被确认的数据报,将这三个同时发给B,
- B成功收到消息后,CLOSED状态关闭并进入SYN-RCVD状态,表示 🔥第一次握手成功,
- 此时 B 知道 A 具有发送消息的功能,但不知道的是A是否有接收信息的功能
- 这时 B 开始发送消息,🔥第二次握手发生了,B的回信 携带TCP头部的信息SYN=1表示我要跟 A 建立同步链接,seq=y表示这次发送的是序号为y的数据报、ACK=1表示 A 的信被确认的数据报, ack=x+1 表示序号为x的数据报已经收到,麻烦下次给我发x+1序号的数据报
- A 知道 B 可以收到自己的消息,但是 B 并不知道 A 已经收到自己的消息,所以 A 需要再次发送消息告诉 B,🔥这时第三次握手发生了,
- B 知道 A 可以收到自己的消息,此时 A 和 B 双方都具有寄信和收信的能力,这一刻AB的连接就建立成功了,连接状态就变成ESTAB-LISHED,表示正常的传输状态,可以互相交流了。😘
连接销毁(四次挥手)
- 当 A 发送消息给 B:"结束链接,是否还有数据",🚀这就是第一次挥手,无论是客户端,还是服务端,都可以发起第一次挥手,我们暂且称为发送方,每一次请求都需要被确认才可以,所以当发送方发起第一次挥手时,发完并不会立刻就挂,而是要等接收方的回应。
- B 收到了 A 的消息,随后回复:“还有数据”,🚀这就是第二次挥手
- 然后 B 发送数据,等 B 发送所有的数据之后,发送:“断开链接”,🚀这是第三次挥手
- B 也并不知道 A 是否收到,所以 A 依然还需要进行回复:“断开链接” 🚀这是第四次挥手
长连接
每次发起一个 HTTP 请求都会创建一个新的 TCP 连接。这种连接方式被称为短连接(short-lived connection)。每个请求都需要经历三次握手建立连接、传输数据以及四次挥手断开连接的过程
然而,由于每次请求都需要耗费时间和资源来建立和断开连接,对于频繁进行请求的场景来说,短连接可能会带来较大的开销。为了解决这个问题,引入了长连接(long-lived connection)
优点
- 减少了建立和断开连接的时间和资源消耗。
- 提高了请求的响应速度,特别是在多次请求时,无需重新建立连接。
- 减少了网络拥堵,因为长连接可以通过单一的连接同时处理多个请求。
应用场景
聊天应用:在实时聊天应用中,客户端与服务器之间可以使用长连接来保持通信通道。这样,在用户之间发送消息时,无需每次都建立新的连接,而是通过现有的长连接进行通信。
实时数据推送:许多实时数据推送应用(如股票市场报价、即时通知等)使用长连接来将实时数据推送给客户端。服务器可以在数据变化时主动推送更新给客户端,而不需要客户端频繁地轮询服务器。
视频流和音频流传输:在视频流和音频流传输中,长连接可以确保持续的数据传输,从而实现无缝的流媒体播放体验。客户端可以通过单一的长连接来接收连续的数据流。
在线游戏:在线游戏通常要求实时的互动和数据传输。使用长连接可以确保玩家之间的实时通信,并减少延迟。
HTTP/2 和 WebSocket:HTTP/2 协议支持多路复用特性,允许在同一个 TCP 连接上并行发送多个请求和接收多个响应。WebSocket 是一种基于 TCP 的双向通信协议,也可以通过长连接实现实时通信。
HTTP 缓存
当客户端发出一个GET请求到服务器,如果一个资源很少变动,可以直接缓存,像那些图片、CSS、JS等资源文件可使用缓存
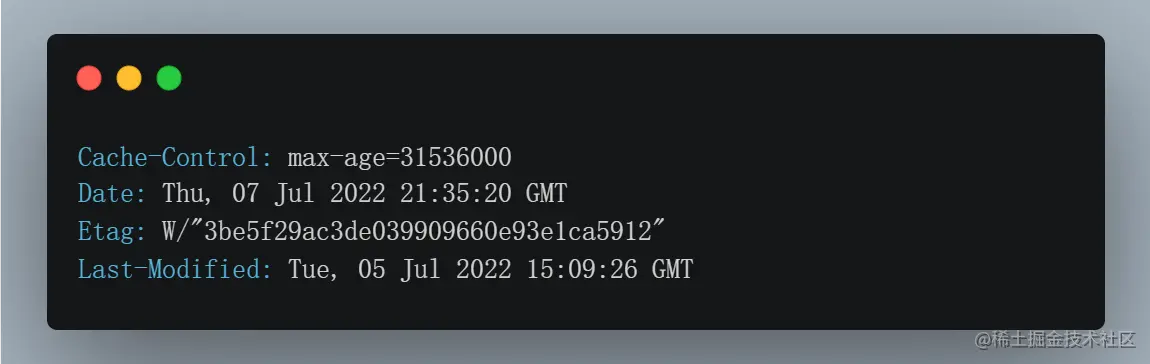
服务器设置一个请求头:
- Cache-Control: max-age=31536000
我希望你可以把这个资源缓存起来,缓存时间为31636000秒(365天)
- Date: Thu, 07 Jul 2022 21:35:20 GMT
我给你响应这个资源的服务器时间是格林威治时间2022-07-07 21:35:20,如果缓存的时间是365天,那就是在此时间上加上365天
- Etag: W/"3be5f29ac3de039909660e93e1ca5912"
这个资源编号是 W/"3be5f29ac3de039909660e93e1ca5912"
- Last-Modified: Tue, 05 Jul 2022 15:09:26 GMT
这个资源上一次修改时间是格林威治时间 2022-07-05 15:09:26
浏览器:
- 浏览器会将这次请求得到的响应体缓存在本地文件中
- 浏览器会记录这次请求的请求方法和请求路径
- 浏览器会记录本次缓存时间是31536000秒
- 浏览器会记录服务器响应时间是格林威治时间2022-07-07 21:35:20
- 浏览器会记录服务器给予的资源编号是W/"3be5f29ac3de039909660e93e1ca5912"
- 浏览器会记录上一次资源修改的时间是格林威治时间 2022-07-05 15:09:26
请求:
首先会判断有没有匹配的缓存,没有就是普通请求
有缓存
- 缓存没有过期
没有过期,使用缓存
过期
- 会在请求头上设置
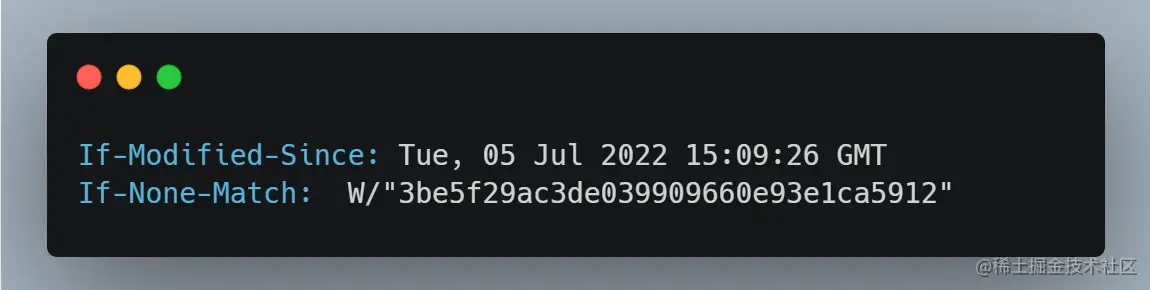
If-Modified-Since和If-None-Match询问服务器文件是否有变化,没变化就直接使用,这种方式叫做 协商缓存(304)
- 会在请求头上设置
- If-Modified-Since: Tue, 05 Jul 2022 15:09:26 GMT
这个资源上一次修改时间是格林威治时间 2022-07-05 15:09:26,不知道在这个时间之后有变动吗?
- If-None-Match: W/"3be5f29ac3de039909660e93e1ca5912"
这个资源编号是 W/"3be5f29ac3de039909660e93e1ca5912" ,请问这个资源编号现在发生改变了吗?
- If-None-Match: W/"3be5f29ac3de039909660e93e1ca5912"
INFO
总结起来就一句话:你快告诉我这个资源到底变了没?之所以要发这两条消息,是为了兼容不同的服务器,因为有的服务器只认If-Modified-Since,而有的服务器只认If-None-Match,有些两个都认。
目前有很多服务器,只要发现
If-None-Match存在,就不会去看If-Modified-Since,If-Modified-Since是http1.0版本规范,If-None-Match是http1.1的规范- 缓存没有过期
Cache-Control
Cache-Control在上面已经说过了,它是服务器向浏览器响应的一个消息头,它提供了一个max-age用于指定缓存时间。实际上它还有其他值可以选择。
- 🚀public:表示服务器资源是公开的,对于浏览器来说并没有什么意义,因为大家看到的东西都是一样的,没有变化,也许在某些场景下有用。
- private:表示服务器资源是私有的,比如某个服务器资源,每个用户看到的都不一样,http协议中很多时候都是客户端或者服务器告诉另一端详细的信息,至于另一端用不用完全自己决定。
- 🌵no-cache:这个值看起来字面意思是不缓存的意思😂,其实不然,它会告诉浏览器,你可以缓存这个资源,但是不要直接使用它。当你缓存后,每一次请求都需要附带缓存指令,每一次请求都需要问一下才行,相当于每一次都是协商缓存
- 🌵no-store:告诉浏览器不要缓存这个资源,后面每一次请求都按照普通请求进行,
- 🚀max-age:这个就不说了吧 😎
浏览器里的缓存都是用户自己的,叫做私有缓存,而代理服务器上的缓存大家都可以访问,叫做公有缓存
如果这个资源只想浏览器里缓存,不想代理服务器上缓存,那就设置 private,否则设置 public:
比如这样设置就是资源可以在代理服务器缓存,缓存时间一年(代理服务器的 max-age 用 s-maxage 设置),浏览器里缓存时间 10 分钟
Cache-control:public, max-age=600,s-maxage:31536000这样设置就是只有浏览器可以缓存:
Cache-control: private, max-age=31536000而且,缓存过期了就完全不能用了么?
Cache-control: max-stale=600stale 是不新鲜的意思。请求里带上 max-stale 设置 600s,也就是说过期 10 分钟的话还是可以用的,但是再长就不行了
数据格式
🔗MIME 类型
媒体类型(也通常称为多用途互联网邮件扩展或 MIME 类型)是一种标准,用来表示文档、文件或一组数据的性质和格式
类型结构
MIME 类型通常仅包含两个部分:类型(type)和子类型(subtype),中间由斜杠 / 分割,中间没有空白字符
type/subtype类型代表数据类型所属的大致分类,例如 video 或 text。
子类型标识了 MIME 类型所代表的指定类型的确切数据类型。以 text 类型为例,它的子类型包括:plain(纯文本)、html(HTML 源代码)、calender(iCalendar/.ics 文件)。
二者必须成对出现。
有一个可选的参数,能够提供额外的信息
type/subtype;parameter=value对于主类型为 text 的任何 MIME 类型,可以添加可选的 charset 参数,以指定数据中的字符所使用的字符集。如果没有指定 charset,默认值为 ASCII(US-ASCII),除非被用户代理的设置覆盖。要指定 UTF-8 文本文件,则使用 MIME 类型 text/plain;charset=UTF-8。
MIME 类型对大小写不敏感,但是传统写法都是小写。参数值可以是大小写敏感的
类型
类型可分为两类:独立的(discrete)和多部分的(multipart)。
独立类型代表单一文件或媒介,比如一段文字、一个音乐文件、一个视频文件等。而多部份类型,可以代表由多个部件组合成的文档,其中每个部分都可能有各自的 MIME 类型;此外,也可以代表多个文件被封装在单次事务中一同发送。多部分 MIME 类型的一个例子是,在电子邮件中附加多个文件。
post
form-data 和 application/x-www-form-urlencoded
application 是类型,x-www-form-urlencoded 是子类型
TIP
- 数据包格式的区别,
- 数据包中非ASCII字符怎么编码,是百分号转码发送还是直接发送
application/x-www-form-urlencoded(编码)
这是一种较旧、较简单的数据编码格式,将表单数据编码为 URL 查询参数的形式
使用 等号分隔键和值,并使用 & 分隔不同字段,然后对特殊字符进行编码(例如空格变为 %20)。这种格式适合传输简单的键值对,并且在 HTML 表单的默认提交 行为中使用
对于Get请求,是将参数转换 ?key=value&key=value 格式,连接到 url 后
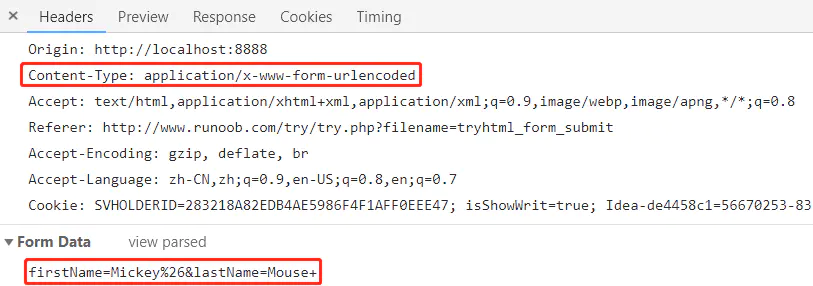
<form action="http://localhost:8888/task/" method="POST">
First name: <input type="text" name="firstName" value="Mickey&"><br>
Last name: <input type="text" name="lastName" value="Mouse "><br>
<input type="submit" value="提交">
</form>如果是非 form 表单形式
const data = {
name: "John",
email: "john@example.com"
};
// 将对象转换为 URL 查询参数的形式
const encodedData = Object.keys(data)
.map(key => encodeURIComponent(key) + "=" + encodeURIComponent(data[key]))
.join("&");
// 发送 POST 请求
fetch("/api/submit", {
method: "POST",
headers: {
"Content-Type": "application/x-www-form-urlencoded"
},
body: encodedData
})
form-data
FormData 接口提供了一种表示表单数据的键值对 key/value 的构造方式
const formElement = document.getElementById("myForm");
const formData = new FormData(formElement);
// 添加额外的字段到 FormData 对象中
formData.append("age", "25");
// 发送 POST 请求
fetch("/api/submit", {
method: "POST",
body: formData
})⭐区别
form-data 可以同时传输多个键值对以及文件数据,而 application/x-www-form-urlencoded 仅支持传输键值对。
form-data 适用于上传文件或包含二进制数据的表单,而 application/x-www-form-urlencoded 更适合传输简单的文本表单数据。
form-data 的数据编码复杂度较高,需要构建一个 FormData 对象,并使用 JavaScript 进行提交,而 application/x-www-form-urlencoded 可以直接在请求的 body 中编码数据。
multipart/form-data
multipart/form-data 是基于 post 方法来传递数据的,并且其请求内容格式为 Content-Type: multipart/form-data,用来指定请求内容的数据编码格式
请求体内容各字段之间以 --${boundary} 来进行分割,以 --${boundary}-- 来结束请求体内容
POST http://www.example.com HTTP/1.1
Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryyb1zYhTI38xpQxBK
------WebKitFormBoundaryyb1zYhTI38xpQxBK
Content-Disposition: form-data; name="city_id"
1
------WebKitFormBoundaryyb1zYhTI38xpQxBK
Content-Disposition: form-data; name="company_id"
2
------WebKitFormBoundaryyb1zYhTI38xpQxBK
Content-Disposition: form-data; name="file"; filename="chrome.png"
Content-Type: image/png
PNG ... content of chrome.png ...
------WebKitFormBoundaryyb1zYhTI38xpQxBK--application/json
axios 中 post 默认使用 json 传输
async function json() {
const res = await axios.post('/api/person', {
name: '光',
age: 20
});
console.log(res);
}
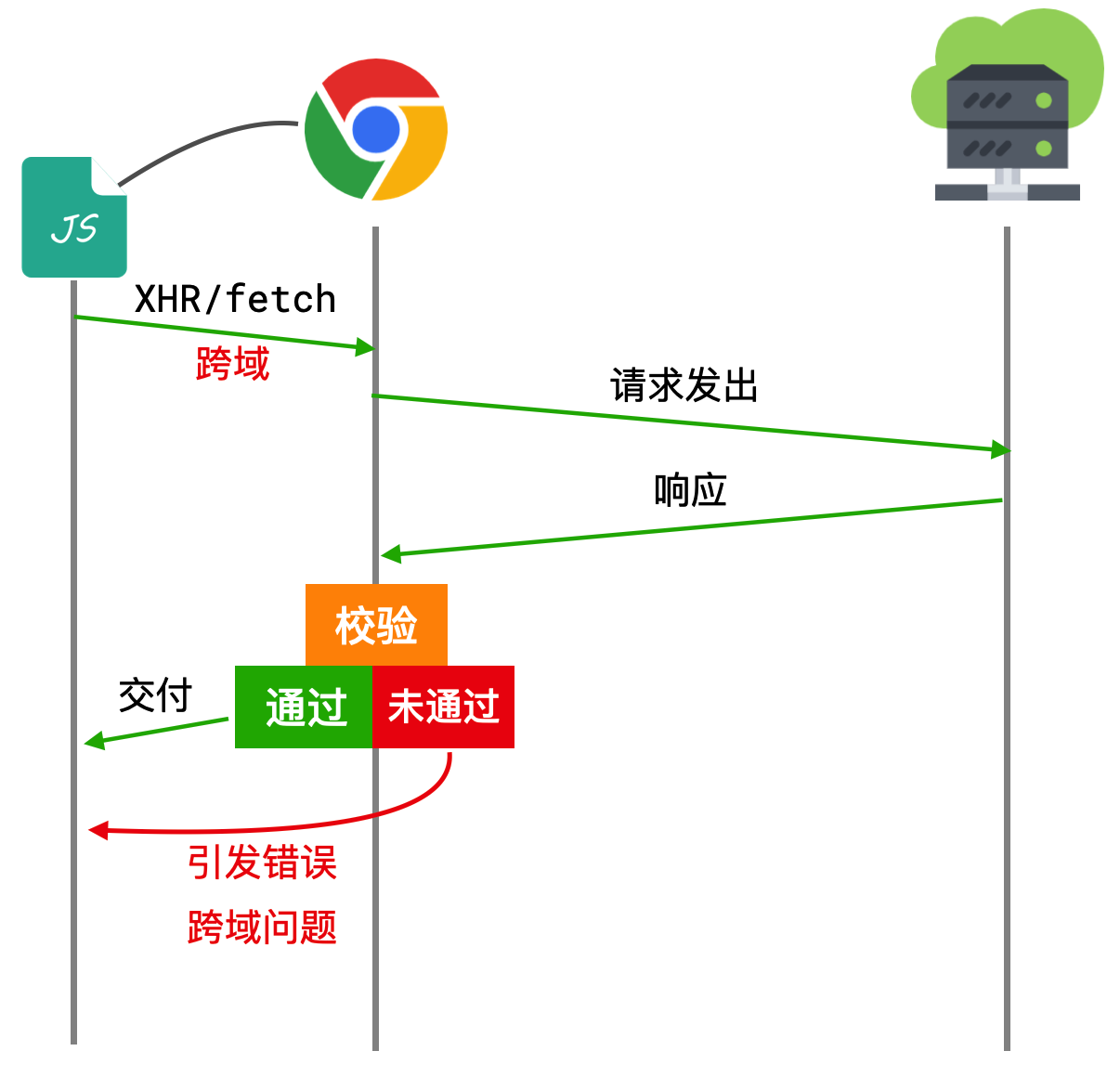
json();🔗跨域
DANGER
虽然跨域,但是服务器依然可以收发响应,只是浏览器拦截了响应
浏览器将CORS请求分成两类:简单请求(simple request)和非简单请求(not-so-simple request)
只要同时满足以下两大条件,就属于简单请求。
(1) 请求方法是以下三种方法之一:
- HEAD
- GET
- POST
(2)HTTP的头信息不超出以下几种字段:
- Accept
- Accept-Language
- Content-Language
- Last-Event-ID
- Content-Type:只限于三个值application/x-www-form-urlencoded、multipart/- form-data、text/plain这是为了兼容表单(form),因为历史上表单一直可以发出跨域请求。AJAX 的跨域设计就是,只要表单可以发,AJAX 就可以直接发。
对于简单请求,浏览器直接发出CORS请求。具体来说,就是在头信息之中,增加一个 Origin 字段

🌲如果 Origin 指定的源,不在许可范围内,服务器会返回一个正常的HTTP回应,浏览器发现,这个回应的头信息没有包含 Access-Control-Allow-Origin 字段,就知道出错了,从而抛出一个错误,注意,这种错误无法通过状态码识别,因为HTTP回应的状态码有可能是200
如果 Origin 指定的域名在许可范围内,服务器返回的响应,会多出几个头信息字段

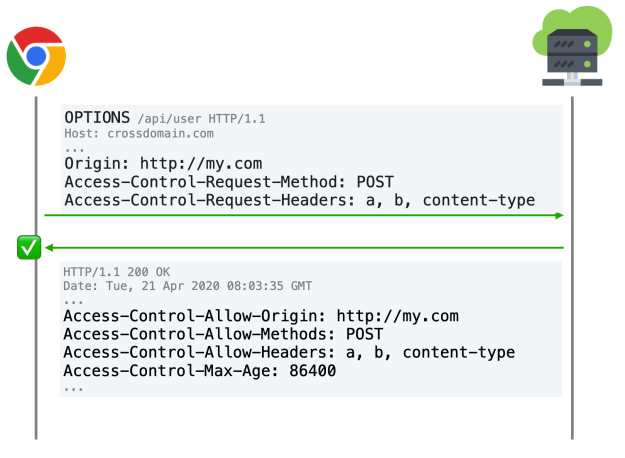
复杂请求需要发送一个 预检请求
对于预见请求,其实就是在发送请求之前,浏览器会先去服务器跑一趟,只携带着请求头,询问服务器是否放行,如果服务器同意,则会发送真实请求
细节
- 关于cookie
默认情况下,ajax的跨域请求并不会附带cookie,需要手动开启
// xhr
var xhr = new XMLHttpRequest();
xhr.withCredentials = true;
// fetch api
fetch(url, {
credentials: "include"
})当一个请求需要附带cookie时,无论它是简单请求,还是预检(preflight)请求,都会在请求头中添加cookie字段
而服务器响应时,需要明确告知客户端:服务器允许这样的凭据
告知的方式也非常的简单,只需要在响应头中添加:Access-Control-Allow-Credentials: true 即可
🐞对于一个附带身份凭证的请求,若服务器没有明确告知,浏览器仍然视为跨域被拒绝。
🦂另外要特别注意的是:对于附带身份凭证的请求,服务器不得设置 Access-Control-Allow-Origin 的值为*。这就是为什么不推荐使用 * 的原因
- 关于跨域获取响应头
在跨域访问时,JS只能拿到一些最基本的响应头,如:Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma,如果要访问其他头,则需要服务器设置本响应头。
Access-Control-Expose-Headers 头让服务器把允许浏览器访问的头放入白名单,例如 服务器回应的其他CORS相关字段如下:
Access-Control-Allow-Methods: GET, POST, PUT //
// 该字段必需,它的值是逗号分隔的一个字符串,表明服务器支持的所有跨域请求的方法
Access-Control-Allow-Headers: X-Custom-Header
// 如果浏览器请求包括Access-Control-Request-Headers字段,
// 则Access-Control-Allow-Headers字段是必需的。它也是一个逗号分隔的字符串,
// 表明服务器支持的所有头信息字段,不限于浏览器在"预检"中请求的字段
Access-Control-Allow-Credentials: true
// 该字段与简单请求时的含义相同。
Access-Control-Max-Age: 1728000
// 该字段可选,用来指定本次预检请求的有效期,单位为秒。上面结果中,有效期是20天(1728000秒),
// 即允许缓存该条回应1728000秒(即20天),在此期间,不用发出另一条预检请求
// Access-Control-Allow-Origin 字段是每次回应都必定包含的否定预检请求
TIP
如果服务器否定了"预检"请求,会返回一个正常的HTTP回应,但是没有任何CORS相关的头信息字段 这时,浏览器就会认定,服务器不同意预检请求,因此触发一个错误,被XMLHttpRequest对象的 onerror回调函数捕获
Referrer-Policy
TIP
当用户在浏览器上点击一个链接时,会产生一个 HTTP 请求,用于获取新的页面内容,而在该请求的报头中,会包含一个 Referrer,用以指定该请求是从哪个页面跳转页来的,常被用于分析用户来源等信息。
但是也有成为用户的一个不安全因素,比如有些网站直接将 sessionid 或是 token 放在地址栏里传递的,会原样不动地当作 Referrer 报头的内容传递给第三方网站
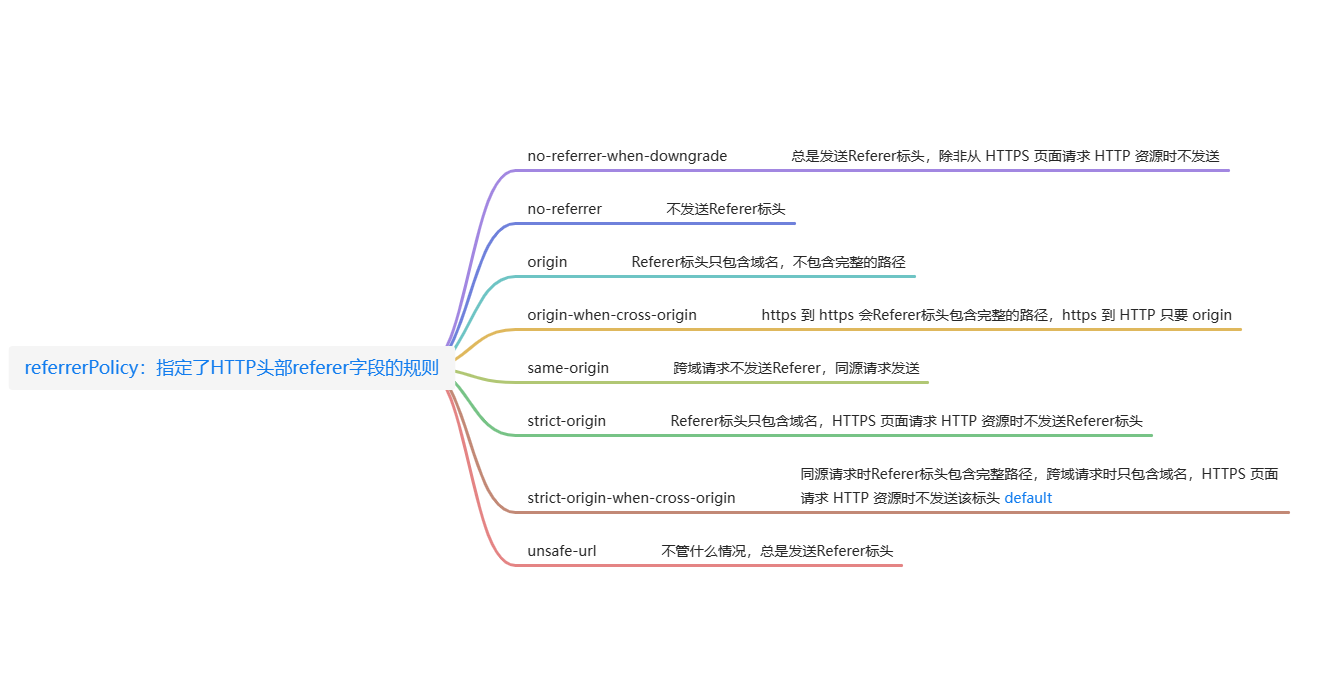
指令值
enum ReferrerPolicy {
"",
"no-referrer",
"no-referrer-when-downgrade",
"same-origin",
"origin",
"strict-origin",
"origin-when-cross-origin",
"strict-origin-when-cross-origin",
"unsafe-url"
}no-referrer 整个 Referer 首部会被移除。访问来源信息不随着请求一起发送。
⭐no-referrer-when-downgrade(默认值) 在没有指定任何策略的情况下用户代理的默认行为。在同等安全级别的情况下,引用页面的地址会被发送 (HTTPS->HTTPS),但是在降级的情况下不会被发送 (HTTPS->HTTP)。
origin 在任何情况下,仅发送文件的源作为引用地址。例如 https://example.com/page.html 会将 https://example.com/ 作为引用地址。
origin-when-cross-origin 对于同源的请求,会发送完整的 URL 作为引用地址,但是对于非同源请求仅发送文件的源。
same-origin 对于同源的请求会发送引用地址,但是对于非同源请求则不发送引用地址信息。
strict-origin 在同等安全级别的情况下,发送文件的源作为引用地址 (HTTPS->HTTPS),但是在降级的情况下不会发送 (HTTPS->HTTP)。
strict-origin-when-cross-origin 对于同源的请求,会发送完整的 URL 作为引用地址;在同等安全级别的情况下,发送文件的源作为引用地址 (HTTPS->HTTPS);在降级的情况下不发送此首部 (HTTPS->HTTP)。
unsafe-url 无论是同源请求还是非同源请求,都发送完整的 URL(移除参数信息之后)作为引用地址。
集成到 HTML
<meta name="referrer" content="origin"><a href="http://example.com" referrerpolicy="origin">
<!-- 或者 -->
<a href="http://example.com" rel="noreferrer">正向代理与 反向代理
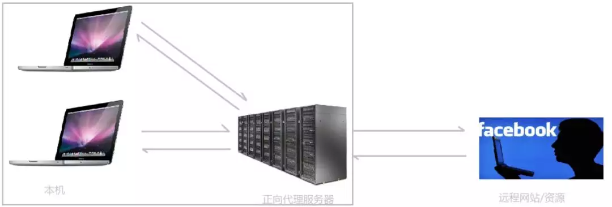
正向代理
如果你去访问 git 的时候,是访问不了的,你 需要 访问 一台可以 访问 git 的服务器 客户端 去 访问 这个代理服务器 ,代理服务器 去访问 git
客户端知道 要访问的是哪个服务器,服务器 只知道 是哪个 代理的服务器访问的 ,并不知道是哪一个 客户端 访问的 客户端必须设置正向代理服务器,当然前提是要知道正向代理服务器的 IP 地址,还有代理程序的端口
定义
总结来说:正向代理,"它代理的是客户端",是一个位于客户端和原始服务器(Origin Server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器)。
然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端必须要进行一些特别的设置才能使用正向代理。
正向代理的用途
- 访问原来无法访问的资源,如 Google。
- 可以做缓存,加速访问资源。
- 对客户端访问授权,上网进行认证。
- 代理可以记录用户访问记录(上网行为管理),对外隐藏用户信息
反向代理
我国的某宝网站,每天同时连接到网站的访问人数已经爆表,单个服务器远远不能满足人民日益增长的购买欲望了 出现了分布式部署,通过多台服务器来解决访问人数限制的问题
定义
多个客户端给服务器发送的请求,Nginx 服务器接收到之后,按照一定的规则分发给了后端的业务处理服务器进行处理了 此时请求的来源也就是客户端是明确的,但是请求具体由哪台服务器处理的并不明确了,Nginx 扮演的就是一个反向代理角色。
反向代理,"它代理的是服务端",主要用于服务器集群分布式部署的情况下,反向代理隐藏了服务器的信息。
反向代理的作用
- 保证内网的安全,通常将反向代理作为公网访问地址,Web 服务器是内网。
- 负载均衡,通过反向代理服务器来优化网站的负载。
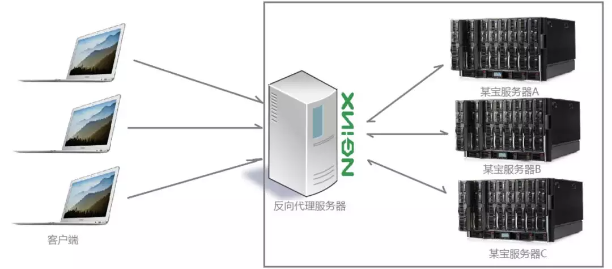
负载均衡
这里提到的客户端发送的、Nginx 反向代理服务器接收到的请求数量,就是我们说的负载量。请求数量按照一定的规则进行分发,到不同的服务器处理的规则,就是一种均衡规则。 所以将服务器接收到的请求按照规则分发的过程,称为负载均衡。
网络攻击
xss
cross site script(跨站点脚本)
将 js 脚本插入到 网页内容中,渲染时执行 js 脚本
方法: 替换特殊字符
csrf
cross site request forgery(跨站请求伪造)
诱导用户请求另一个网站
有一个a 网站,点击按钮 到 b 网站,在 b 网站的时候 ,并发起 a 网站的请求,a 网站会以为是用户自己发起的
比如:一个 gmail 网站,点击按钮到 b网站,在b网站中 转发邮件,由于 带了 a 网站的 cookie ,所以可以执行
方法:预防 跨域 sameSite, 验证码,referrer
click jacking 点击劫持
界面上蒙了一层透明的 iframe,诱导去点击 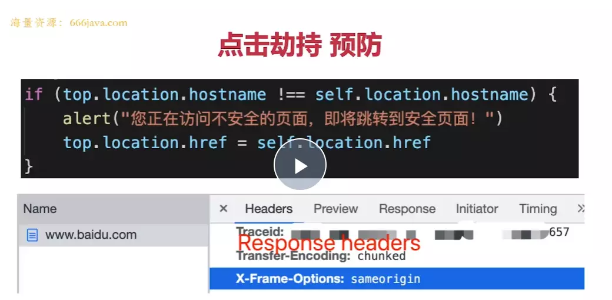
并行 / 并发
并发是指一个处理器同时处理多个任务。
并行是指多个处理器或者是多核的处理器同时处理多个不同的任务。
并发是逻辑上的同时发生(simultaneous),而并行是物理上的同时发生。
来个比喻:并发是一个人同时吃三个馒头,而并行是三个人同时吃三个馒头。
并行是真正的并行,而并发是宏观上并行、微观上串行。进程和线程
每一个程序都有一个进程。
我们可以把一个软件理解为一个家庭,那么这个家庭就是一个进程。
我们家就是一个进程,在这个进程中,有三口人:我、我爸、我妈。
村长就是操作系统
村长是可以指挥单独一个人去做一件事的,那么这个人就叫做一个线程。
那么,村长能单独调动的最小单位就不是一个家庭了,而是一个人。
也就是说:线程是操作系统能调度的最小单元
到这里,我们就知道了:每个程序都有一个进程,线程是进程的一部分,线程是操作系统能调度的最小单元。
上了线程后,我们每个人都是一个线程,就可以三个人一起上,这样时间直接变为原来的 1/3
所以,引入线程,就等价于变串行为并行,能提高速度,节省时间
- 串行:一件事同一时刻只有一个人做。
- 并行:一件事同一时刻有多个人做。
一个 16 核的 CPU,最多只能让 16 个线程同时工作。即使开了 100 个线程,同一个时刻也是只有 16 个线程同时工作
渲染顺序
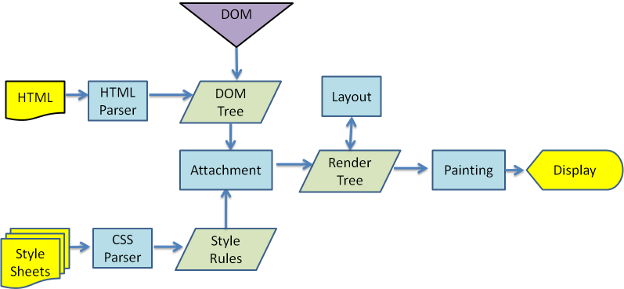
- css加载不会阻塞DOM树的解析
由浏览器的渲染流程图可知,DOM 解析和 CSS 解析是两个并行的进程,所以 CSS 加载不会阻塞 DOM 树的解析
- css加载会阻塞DOM树的渲染(Render Tree)
Render Tree是依赖于 DOM Tree 和 CSSOM Tree 的,所以无论 DOM Tree 是否已经完成,它都必须等待到 CSSOM Tree 构建完成,即 CSS 加载完成(或 CSS 加载失败)后,才能开始渲染。
<head>
<script>
document.addEventListener('DOMContentLoaded', () => {
var p = document.querySelector('p')
console.log(p)
})
</script>
<link rel="stylesheet" href="./static/style.css?sleep=3000">
</head>
<body>
<p>hello world</p>
</body>
CSS 的加载并没有阻塞 DOM 树的解析,p 标签是正常解析的,但 p 标签加载完后,页面是迟迟没有渲染的,是因为 CSS 还没有请求完成,在 CSS 请求完成后,hello world 才被渲染出来,所以 CSS 会阻塞页面渲染
DOMContentLoaded:只有当纯 HTML 被完全加载以及解析时,DOMContentLoaded 事件会被触发,它不会等待样式表,图片或者子框架完成加载
- css加载会阻塞后面js语句的执行
CSS加载会阻塞后面JS语句的执行:在默认情况下,当浏览器加载和解析CSS文件时,会阻塞后续的JavaScript执行。这是因为JavaScript可能会依赖于CSS样式来操作和修改页面元素,所以浏览器需要确保在执行JavaScript之前所有相关的CSS规则已经被解析。
- JS 的加载、解析与执行会阻塞 DOM 的构建
JS 的加载、解析与执行会阻塞 DOM 的构建,也就是说,在构建 DOM 时,HTML 解析器若遇到了 JS,那么它会暂停构建 DOM ,将控制权移交给JS引擎,等 JS 引擎运行完毕,浏览器再从中断的地方恢复 DOM 构建
JS 不只是可以改 DOM , 它还可以更改样式, 也就是它可以更改 CSSOM,那么在执行 JS 时, 必须要能拿到完整的CSSOM。
- 外部 css 和 外部 js
HTML 文件中包含了 CSS 的外部引用和 JS 外部文件,HTML 同时发起这两个文件的下载请求,不管 CSS 文件和 JS 文件谁先到达,都要先等到 CSS 文件下载完成并生成 CSSOM,然后再执行 JavaScript 脚本,最后再继续构建 DOM,构建布局树,绘制页面。